はじめに
朝、目が覚めて窓の外から「ざーざー」という音が聞こえたら、私たちは自然と「雨が降っているな」と理解します。 また、どこからともなく「にゃー」という音が聞えれば、「猫が鳴いている姿」を思い浮かべるでしょう。
私たちはこのように、音をそのまま聞くだけで意味や状況を思い描き、それを言葉として理解することができます。 つまり、音と意味、音と言葉が、頭の中で自然に結びついています。
では、AI にも同じことはできるのでしょうか?音を「波形」や「数値」として扱うだけでなく、言葉と対応づけることは可能なのでしょうか?
こうした音と言葉の対応構造を AI にもたらす試みの一つが「CLAP (Contrastive Language-Audio Pretraining)」です。 CLAP は、音とテキスト(自然言語)とを同じ意味空間に配置し、両者の対応関係を学習する機械学習モデルです。
この仕組みにより、「この音はどの言葉で表せるか」「この文章に合う音はどれか」といった、音と言語をまたぐタスクが可能になります。
この記事では、CLAP がどのように音と言葉の対応関係を学習しているのかを概観しつつ、実際に CLAP を使うとどんなことができるのかを具体例とともに紹介します。
CLAP が音とテキストを対応付ける仕組み
CLAP は音とテキストとを同じベクトル空間にマッピングする技術です。 音とテキストのペアを訓練データとし、音とテキストをそれぞれエンコーダで埋め込みベクトルに変換、対照学習を用いることで音とテキストの対応を学習します。
訓練済みの CLAP モデルは、例えば下記のようなタスクへの適用が考えられます。
| タスク | 典型的なユースケース |
|---|---|
| ゼロショット音タグ付け | 未知クラスの環境音を「chainsaw」「meowing」など自由語彙でラベリングする |
| テキスト → 音検索 | 「雨音のサウンド」を検索して効果音を探す |
| 音 → テキスト検索/キャプション | 音声ファイルに最適な説明文を付与しメタデータ補完に利用する |
| マルチモーダル統合 | 映像・画像・音を同時に扱う AV タスクに適用する |
このように、いろいろな音-テキストタスクに適用できる CLAP ですが、その仕組みはどうなっているのでしょうか? ここからは CLAP がどう作られているのかを掘り下げてみていきます。
基本的な構造と訓練の流れ
CLAP は音とテキストそれぞれを埋め込みベクトルに変換するエンコーダと、それらの埋め込みベクトルを共通のベクトル空間に射影する射影層からなるモデルです。
音とテキストのペアを訓練データとして、大きく次の流れで訓練が進みます。
- 音とテキストをそれぞれのエンコーダで埋め込み表現に変換する(厳密には音はログメルスペクトログラム画像データとして表現されており、それが埋め込まれる)
- それぞれの埋め込みをベクトル空間に線形射影する
- 対照学習により、似ているもの同士は近く、似ていないものは離れるように、エンコーダと線形射影、温度パラメータを訓練する
訓練後は、学習済みのエンコーダ及び射影層、温度パラメータを使って音とテキストを埋め込みに変換し、音の埋め込みとテキストの埋め込みとの類似度をとることによって、zero-shot 分類などのタスクに利用することができます。
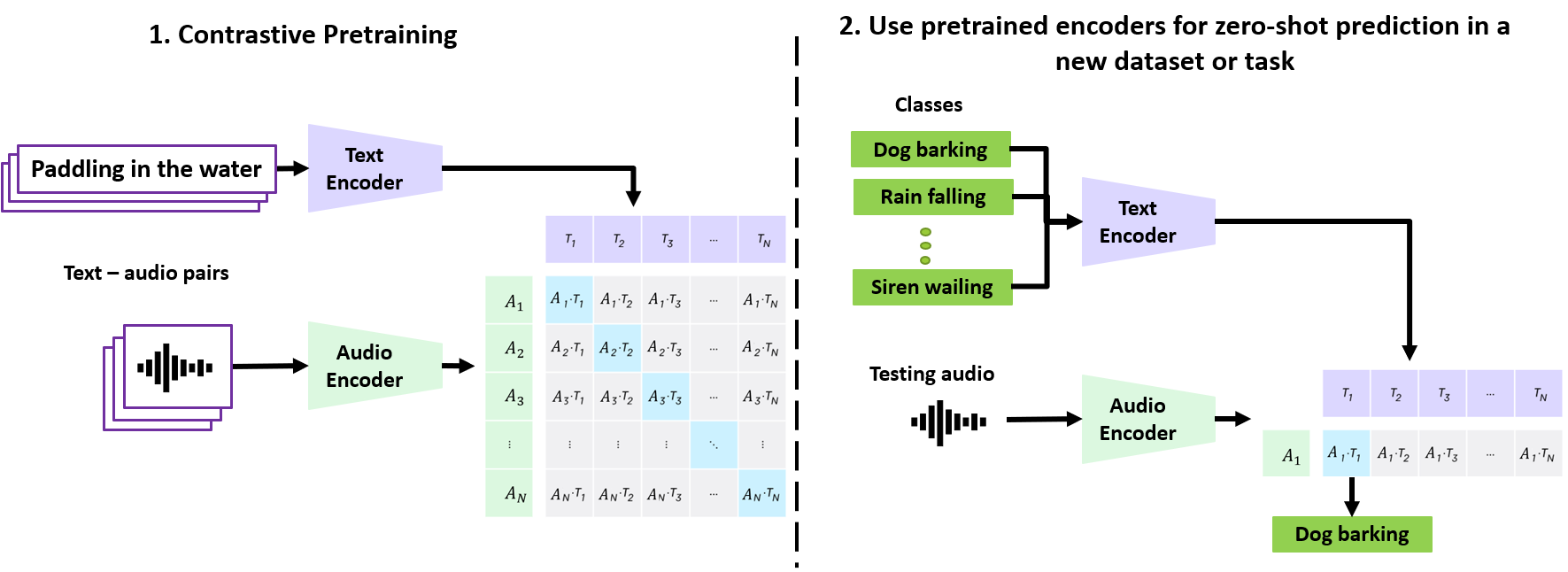 CLAP のイメージ。CLAP: Learning Audio Concepts From Natural Language Supervision より引用。
CLAP のイメージ。CLAP: Learning Audio Concepts From Natural Language Supervision より引用。
音-テキストの対照学習
では、CLAP で具体的にどのような訓練がなされているか詳しくみていきます。
学習用の音声-テキストペアデータセットを とします。 は音声データ(をログメルスペクトログラムに変換した画像データ)で、 と はそれぞれスペクトル要素の数(周波数方向の bin の数)と時間ステップ(時間方向の bin の数)を表します。 はテキストデータを表します。
音声とテキストデータはそれぞれ音声用のエンコーダ とテキスト用のエンコーダ を通って埋め込みに変換されます。
と はそれぞれ音埋め込みとテキスト埋め込みの次元の数であり、一般に です。
この状態ではまだ音とテキストとはただ別々にベクトル化されただけです。 ここから音とテキストとをうまく対応づけるため、同じベクトル空間にマッピングする操作を施します。 つまり、埋め込みの次元を揃えて同じベクトル空間で扱うような線形射影により、 次元ベクトル空間へ飛ばします。
と はそれぞれ音とテキストの線形射影であり、学習対象です。 以降は と をそれぞれ音の埋め込み、テキストの埋め込みと呼ぶこととします。
ここまでで、音とテキストとの対応付けをする準備が整いました。 ここから、音とテキストの対応付けを具体的に見ていきます。
さて、 と が同一次元を持つということは、これらの類似度(関連性の度合い)が計算できるということです。つまり、
ここで は(逆)温度パラメータで学習対象です(ログでスケーリングします)。 は類似度行列で、 個の正解ペアを対角にもち、 個の不正解ペアを非対角成分に持つように構成されています。 この類似度行列を使い、正解ペアの類似度が高く、不正解ペアの類似度が低くなるようにエンコーダと射影、温度を学習することで、音とテキストとの対応付けを訓練しようというわけです。
訓練のために損失関数を定義します。 CLAP では、類似度行列 について、テキスト方向と音方向の 2 方向から InfoNCE ロスを計算し、平均したものを最終損失とします。
ここで、 はテキスト方向の損失で次式で与えられます。
各行 について、正例が列 の要素に対応します。 のソフトマックスを取った後の確率をクロスエントロピーで評価します。
同様に は音方向の損失で次式で与えられます。
実は、この損失関数を最小化するように学習を進めることで、正例ペアの類似度は高く、不例ペアの類似度は低くなるようになります。 つまり、対応する音-テキストペアは類似度が高くなるが、対応しないペアについては類似度が低くなるように学習が進むということです。 これが CLAP が音-テキスト対応を可能とする核となる部分です。
最適解における類似度行列の形
ここからさらに計算を進め、損失関数が最小となる最適解において、正例ペアの類似度が高く、負例ペアの類似度は低くなることをみていきます。 表記を簡単にするため、 と の内積を と表すことにします。つまり、
また、埋め込み の大きさは に吸収できるので、以降では とします。
最適解での類似度の様子をみるためには、損失関数の での勾配が 0 になるような ないし の表式をみれば良いということです。 計算すると
となるので、 より、 、すなわち、
よって、最適解としては類似度行列について
である必要があるとわかります。 また、 なので、 から はその上限値である をとって欲しいこともわかります。
したがって、最適解における類似度は
となります。 この表式から、対応する音-テキストペア(正例)の類似度は高く、それ以外(負例)は低くなるように学習が進むということがわかりました。
実験
ここまでで、CLAP が音とテキストを対応づける仕組みについてみてきました。
ここからは、CLAP の実力を見つつ理解を深めるため、実際のデータを使って簡易的な実験・観察をしてみます。 今回、 モデルにはLAIONが出している laion/clap-htsat-unfused を利用しています。
なお、一連の実験コードは本記事の一番最後、付録:実験コードにおいています。
実験 1: 音声データからの特定音声の検出
CLAP は音声とテキストとを対応づけます。 この性質を使うことで、特定の音声をテキストを使って見つけることができそうです。 そこで今回は、時系列音声データの中で特定の音声が生じている箇所を、テキスト指定によって検出してみます。
手順
次のような手順を取ります。
- 対象となる音声データと、そこから検出したい音の内容を記載したテキストを用意します。
- 音声データを 1 秒間隔ごとに 3 秒間の窓で区切り、その区間内の音の埋め込みとテキストの埋め込みとのコサイン類似度を各秒数ごとに計算します。
- 音声データ全体のうち、類似度が高めに出ている区間があれば、そのタイミングでテキストに対応する音が流れていると判定します。
本来は閾値を何らかの方法で決めた上で、閾値以上の類似度がみられる区間を検出箇所とするべきですが、今回は簡易的な実験なので、閾値は決めずに類似度の値の大小だけを観察します。
利用データ
実験には「水辺で鳥が鳴いている様子」を収めたデータを使用します。(個人的に録音したものです。)
この 30 秒ほどの音声データには、基本的に水が流れている音が入っているのですが、2 秒目〜6 秒目あたりにのみ鳥の鳴き声が混じっています。 CLAP(とテキスト)を使うことで、この音声データのうち鳥が鳴いた箇所を検出できそうかを見ていきます。
音声との類似度をとるテキストとしては "Birdsong"(鳥の鳴き声), "Water flowing"(水の流れ), "Dog barking"(犬の吠え声) の3つを試します。 鳥の鳴き声を検出するだけであれば、埋め込むテキストとしては"Birdsong"だけでいいのですが、他二つも参考のため追加しています。(特に"Dog barking"は音声データとは全然関係のないテキストとの類似度を観察するために入れています。)
結果と考察
早速、実験結果を見ていきましょう。 図は上から、音声データの波形、メルスペクトログラム、音とテキストとの類似度の遷移を図示したものです。
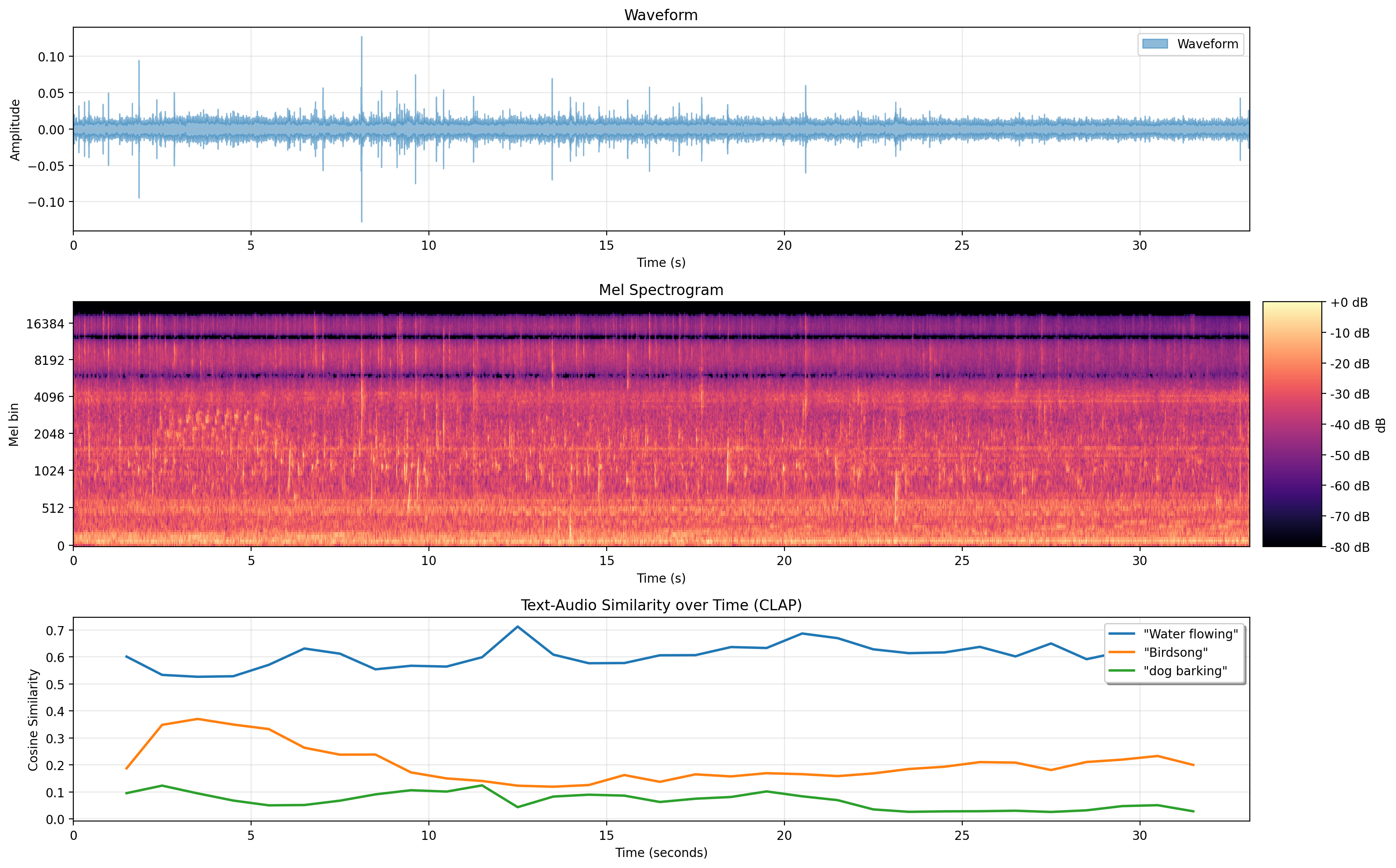 音声データの波形(上)、メルスペクトログラム(中)、各スライディング窓ごとに計算した各種テキストと音声との類似度推移(下)
音声データの波形(上)、メルスペクトログラム(中)、各スライディング窓ごとに計算した各種テキストと音声との類似度推移(下)
音の波形からはどこで鳥が鳴いたかは、ほぼ見分けがつかないかと思います。(少なくとも自分は見分けがつかないです。) メルスペクトログラムを見ると横軸 2〜6 秒、縦軸 1024〜4096 のあたりに細かいギザギザの怪しい山が見えますが、ここが鳥の鳴き声かと言われると微妙です。 一方、音とテキストの類似度の遷移を表した図を見てみると、"Birdsong"というテキストと音声の類似度が 2〜6 秒頃だけ高めに出ていることがわかります。 この区間はまさに、実際の音声データでも鳥が鳴いていた箇所に対応しています。 したがって、類似度が高くなっている箇所を見つけることによって、鳥が鳴いていた箇所を見分けることができています。
さらに、参考のため追加したテキストの類似度についてもみてみます。 まず、"Water flowing"についてですが、基本的に類似度が高く、音声全体を通して常に水が流れていることを捉えることができています。 次に、今回の音声とは全然関係ない"Dog brarking"ですが、全体的に類似度が低く、犬の鳴き声が今回の音声に含まれていないこともうまく汲み取れています。
以上の結果は、CLAP が音とテキストとをうまく対応づけられている実力といえます。
実験 2: 音-テキスト対応の観察
CLAP では音とテキストとを同じベクトル空間にマッピングすることで、対応づけていました。 したがって、互いに意味の近い音とテキストとが、ベクトル空間の近い位置に埋め込まれることが期待されます。 そこで、音とテキストの埋め込みベクトルの様子を観察してみましょう。
利用データ
ここでは、ESC-50 という音-テキストラベルデータを使い、音とテキストデータを CLAP で埋め込んだ様子を観察します1。 このデータセットでは、5 種類のメジャーカテゴリごとに 10 種類のサブクラスが存在し、各サブクラスごとに 5 秒間の音声が 40 個格納されています。
手順
観察の手順は次のとおりです。
- データセット中のサブクラスのテキストと音声データをそれぞれ CLAP で埋め込みベクトルに変換します。
- ただし、サブクラスのテキストは単語や単語をアンダースコアで繋いだものになっているため、今回はサブクラス名を自然言語風に加工した上で埋め込むようにしています。
- 例えば、"sea_waves"というサブクラスについては、"The sound of a sea waves."と加工した上で埋め込みベクトルに変換する、といった具合です。
- 各ベクトルを UMAP を使って 2 次元に次元圧縮します。CLAP で埋め込んだベクトルは高次元で、そのままでは可視化が難しいためです。
- 次元圧縮した各埋めこみベクトルを 2 次元平面上にプロットして、テキストと音声データの対応を可視化します。
結果と考察
結果の図がこちらです。 丸い点(●)が音声の埋め込みベクトル、三角の点(▲)がテキストラベルの埋め込みベクトルです。(ただし次元圧縮後のものです) グレーの線は、元のデータセット時点で各音声に与えられているサブクラステキストがどれかを指しています。 点の色は各データが属するメジャーカテゴリを表します。
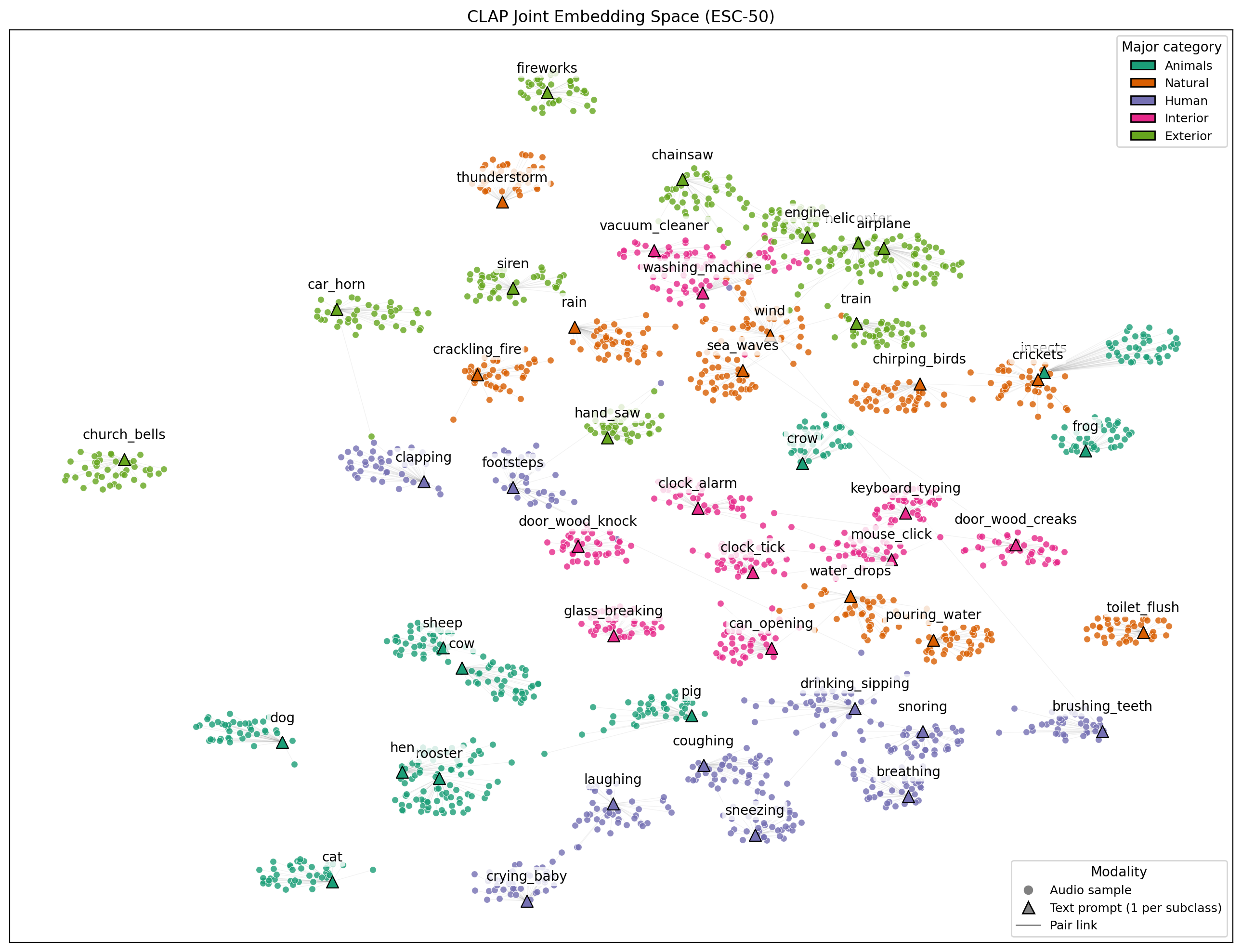 データセットの埋め込みベクトルを次元圧縮して可視化した結果。丸記号(●)と三角記号(▲)の点はそれぞれ音声とテキストを表し、データセットで与えられている音-テキスト対応はグレーの線で示している。点の色により、各データに元々ラベリングされていたメジャーカテゴリを区分している。次元圧縮には UMAP を利用している。
データセットの埋め込みベクトルを次元圧縮して可視化した結果。丸記号(●)と三角記号(▲)の点はそれぞれ音声とテキストを表し、データセットで与えられている音-テキスト対応はグレーの線で示している。点の色により、各データに元々ラベリングされていたメジャーカテゴリを区分している。次元圧縮には UMAP を利用している。
大域的構造
全体を通して、CLAP が音声とテキストを同一の意味空間上にうまく整列させている様子が見て取れます。
まず、メジャーカテゴリごとに、空間上でゆるいクラスタが形成されています。カテゴリごとの完全な分離ではないものの、「Animals は生物の発する音(鳴き声)としてまとまる」「Human は身体動作・発声に関わる音として近接する」「Interior/Exterior は環境音・人工音として比較的広い領域に分布する」といった、人間の直感に近い構造が自然に現れているように見えます。
また、各サブクラスのテキスト周囲には、対応する音声サンプルがまとまって分布する傾向も見られます。 つまり、対応する音とテキストの一致が大域的に成り立っています。
加えて、メジャーカテゴリを横断した対応関係も見られます。 例えば、Natural カテゴリの chirping_birds が Animal カテゴリの crow の近くに分布していたり、Animals カテゴリの crikets が Natural カテゴリの insects の近くにいたりと、類似したサブクラス同士が近くなる傾向が見られます。
これらの様子から、CLAP は単なる音響的特徴(スペクトル形状など)だけでなく、「その音が何を意味するのか」という意味情報もある程度捉えられていると考えられます。
局所的構造
意味的に近いクラス同士の配置に着目してみると、CLAP が「音の発生源」や「聴覚的な類似性」を捉えていることがわかります。
実際、「rain, sea_waves, wind」「keyboard_typing, mouse_click, clock_tick」「breathing, snoring, coughing, sneezing」といったクラスは、物理的・意味的に近い音ですが、空間上でも互いに近接して配置されています。
一方、クラス間の曖昧さ・重なりに着目すると、完全に分離しきれていないクラスも存在することがわかります。 つまり、現実世界における音の曖昧さも、そのまま埋め込み空間に反映されているということです。 例えば、engine / helicopter / airplane のような機械音や、water_drops / pouring_water / toilet_flush のような水音は、局所的に混ざり合う傾向が見られます。
このように、CLAP は、局所的には現実世界の音の類似性・曖昧さもうまく反映していると考えられます。
類似度行列の観察
上記の結果はあくまで次元圧縮した後のベクトルを観察したものなので、元の高次元ベクトル空間での直接的な比較にはなっていません。 別の角度から音-テキスト対応を観察するため、次元圧縮前の音埋め込みとテキスト埋め込みについて総当たりで類似度を取ったヒートマップをみてみましょう。
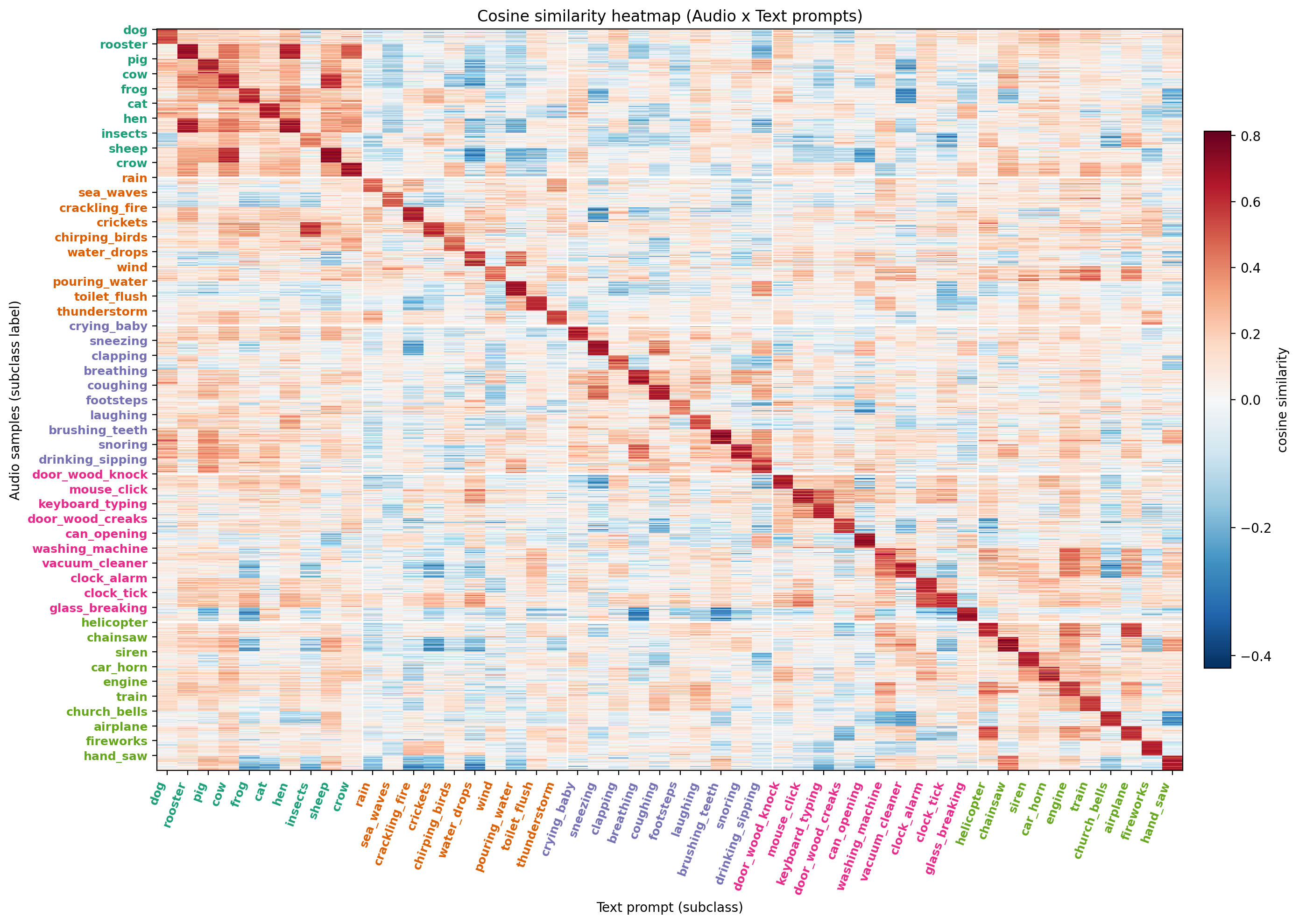 音データとサブクラステキストの埋め込みベクトルとの類似度行列。縦軸が音声、縦軸がサブクラステキストを表し、セルの値は音声とサブクラステキストのそれぞれの埋め込みベクトル間のコサイン類似度値を表す。
音データとサブクラステキストの埋め込みベクトルとの類似度行列。縦軸が音声、縦軸がサブクラステキストを表し、セルの値は音声とサブクラステキストのそれぞれの埋め込みベクトル間のコサイン類似度値を表す。
図の縦軸は音声データ、横軸が各サブクラステキストを表し、各セルの値が音とテキストそれぞれの埋め込みベクトル同士の類似度を表します。
対角成分が一貫して高い類似度となっており、音声が元々付与されていたサブクラステキストとの結びつきが強いことがわかります。 CLAP が音とテキストの対応関係をうまく獲得できているためだと考えられます。
また、メジャーカテゴリによっては、カテゴリ内の要素同士が比較的高めの類似度を持つブロック構造も観察されます。 例えば、Animals カテゴリに着目すると、互いに対応しない音声とサブクラステキスト同士でも比較的高めの類似度がみられます。 したがって、CLAP は完全一致だけでなく、意味的に近い音声・テキスト同士もある程度近づくような連続的な表現空間を持っていることがわかります。
さらに細かくサブクラス単位で見ると、一部の本来対応しない音声-テキスト間にも比較的高い類似度がみられます。 例えば、rooster(オンドリ)と hen(鶏)、crickets(コオロギ)と insects(昆虫)、helicopter(ヘリコプター)と airplane(飛行機)といった組で、類似度が高めに出ています。 これらは互いに意味的・音響的に近しいものになっており、人が似ていると考えるものを CLAP も似ていると表現できているために生じた結果と考えられます。
一方、対角線から離れた領域では、全体的に低めの類似度が支配的になっていることもわかります。 CLAP のもつ表現空間が、「動物の音声と機械的な音声」「人体の音声と環境音」のような意味的・音響的に全く異なるもの同士を区別・分離する性質も持ち合わせていることを示唆しています。
まとめ
本記事では、音とテキストを対応づける技術である CLAP(Contrastive Language-Audio Pretraining)を取り上げ、仕組みの概観から簡易的な実験・観察までを行いました。
CLAP は対照学習によって、音をただの波形としてではなく、「どの言葉と結びついているか」という形で意味空間に配置するモデルです。 実験結果からも、テキストから音を探り当てる様子や、対応する音とテキストが近くに配置され、意味的に似た音同士が連続的に並ぶ様子が確認できました。 一方、クラス間の混ざりや曖昧さも見えました。これは、現実世界での音や言語の曖昧さの反映で、表現モデルとしての自然な性質とも捉えられそうです。
総じて、CLAP は音とテキストの意味的な対応や検索に強みを持つモデルだと思います。 音検索やメタデータ付与などの音-テキスト対応タスク、さらには他のモダリティとの統合や生成モデルなど、言葉で音を扱う方向性の今後が楽しみです。
参考文献
- CLAP: Learning Audio Concepts From Natural Language Supervision
- Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation
- laion/clap-htsat-unfused
- ESC: Dataset for Environmental Sound Classification
付録:実験コード
実験1コード
import torch
import librosa
import librosa.display
import numpy as np
import matplotlib.pyplot as plt
from transformers import ClapModel, ClapProcessor
from typing import List, Tuple, Optional
from google.colab import files
import matplotlib.gridspec as gridspec
# 高解像度なPNGでグラフを出力するための設定
import matplotlib_inline.backend_inline
matplotlib_inline.backend_inline.set_matplotlib_formats("retina")
# ============================================================
# デバイス設定
# ============================================================
def setup_device() -> torch.device:
"""PyTorch の実行デバイス(CPU または CUDA)を取得する。
Returns:
torch.device: 使用するデバイス
"""
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
return device
# ============================================================
# CLAP モデルのロード
# ============================================================
def load_clap_model(
device: torch.device,
model_id: str = "laion/clap-htsat-unfused",
) -> Tuple[ClapModel, ClapProcessor]:
"""CLAP モデルとプロセッサをロードする。
Args:
device (torch.device): モデルを配置するデバイス
model_id (str): Hugging Face上のCLAPモデルID
Returns:
Tuple[ClapModel, ClapProcessor]: ロード済み CLAP モデルとプロセッサ
"""
print("Loading CLAP model...")
model = ClapModel.from_pretrained(model_id).to(device)
processor = ClapProcessor.from_pretrained(model_id)
print("Model loaded.")
return model, processor
# =========================================================
# 音声アップロード & 読み込み
# =========================================================
def process_audio_data() -> Tuple[Optional[np.ndarray], Optional[int], Optional[float]]:
"""
ColabのファイルアップロードUIから音声ファイルを選択し、librosa で読み込んで波形を返す。
Returns:
Tuple[audio_data, sr, total_duration]
audio_data: 1次元 np.ndarray (モノラル波形) or None
sr: サンプリングレート or None
total_duration: 音声長 (秒) or None
"""
print("Please upload file (.wav, .mp3, .mp4, etc, ... )")
uploaded = files.upload()
if not uploaded:
print("Upload canceled. Stop Processing")
return None, None, None
# アップロードされた最初のファイル名を取得
file_name = list(uploaded.keys())[0]
print(f"\nProcessing: {file_name}")
print("Loading audio...")
try:
audio_data, sr = librosa.load(file_name, sr=48000) # CLAP推奨サンプリングレートを使用
total_duration = len(audio_data) / sr
print(f"Load complete. Total duration: {total_duration:.2f} seconds")
return audio_data, sr, total_duration
except Exception as e:
print(f"Error: {e}")
print("The file format may not be supported.")
return None, None, None
# =========================================================
# 類似度計算
# =========================================================
def compute_similarity_over_time(
device: torch.device,
model: ClapModel,
processor: ClapProcessor,
audio: np.ndarray,
sr: int,
texts: List[str],
win_sec: float,
step_sec: float,
) -> Tuple[np.ndarray, np.ndarray]:
"""
音声全体をスライディングウィンドウで走査し、
各時間窓におけるテキストとのコサイン類似度を計算する。
Args:
model (ClapModel): 事前学習済み CLAP モデル
processor (ClapProcessor): CLAP 用の前処理プロセッサ
audio (np.ndarray): 1 次元の音声波形
sr (int): サンプリングレート
texts (List[str]): 類似度を測りたいテキストのリスト
win_sec (float): 1 つの窓の長さ(秒)
step_sec (float): 窓をずらすステップ幅(秒)
Returns:
Tuple[np.ndarray, np.ndarray]:
- timestamps: 各窓の中心時刻(秒) shape = (num_windows,)
- similarities: 各窓 × 各テキストの類似度
shape = (num_windows, num_texts)
"""
win_samples = int(win_sec * sr)
step_samples = int(step_sec * sr)
if len(audio) < win_samples:
raise ValueError(
f"Audio signal is too short: "
f"window_size_sec={win_sec:.2f} s, "
f"but audio length is only {len(audio) / sr:.2f} s."
)
# テキストの特徴量を事前にまとめて計算
inputs_text = processor(text=texts, return_tensors="pt", padding=True)
with torch.no_grad():
text_embeds = model.get_text_features(**inputs_text.to(device))
# ベクトルの長さで割って L2 正規化(方向=意味だけを見るため)
text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
probs_over_time: List[np.ndarray] = []
timestamps: List[float] = []
# スライディングウィンドウのステップ数
num_steps = int((len(audio) - win_samples) / step_samples) + 1
print(f"Processing {num_steps} windows...")
for i in range(num_steps):
start = i * step_samples
end = start + win_samples
chunk = audio[start:end]
# 音声の特徴量を計算
inputs_audio = processor(audios=chunk, sampling_rate=sr, return_tensors="pt")
with torch.no_grad():
audio_embeds = model.get_audio_features(**inputs_audio.to(device))
audio_embeds = audio_embeds / audio_embeds.norm(p=2, dim=-1, keepdim=True)
# コサイン類似度を計算(正規化済み同士なので内積がコサイン類似度になる)
similarity = torch.matmul(audio_embeds, text_embeds.T)
# 値をリストに追加
probs_over_time.append(similarity.cpu().numpy()[0])
# 窓の中心時刻をタイムスタンプとする
timestamps.append(start / sr + win_sec / 2.0)
return np.array(timestamps), np.array(probs_over_time)
# =========================================================
# 可視化
# =========================================================
def plot_similarity_over_time(
audio_data: np.ndarray,
sr: int,
total_duration: float,
timestamps: np.ndarray,
similarities: np.ndarray,
text_queries: List[str],
) -> None:
"""
波形 / メルスペクトログラム / 類似度推移を 1 つの図にまとめて描画する。
"""
fig = plt.figure(figsize=(16, 10))
# 全体は 3 行 × 2 列(右側はカラーバー専用の細い列)
gs = gridspec.GridSpec(
3, 2,
width_ratios=[1, 0.05], # 左を広く、右はカラーバー用に細く
height_ratios=[1, 1.2, 1] # 必要に応じて微調整
)
# --- 1段目:波形の描画 ---
ax1 = fig.add_subplot(gs[0, 0])
librosa.display.waveshow(audio_data, sr=sr, alpha=0.5, label="Waveform", ax=ax1)
ax1.set_title("Waveform")
ax1.set_xlim(0, total_duration)
ax1.set_xlabel("Time (s)")
ax1.set_ylabel("Amplitude")
ax1.grid(alpha=0.3)
ax1.legend(loc="upper right")
# --- 2段目:メルスペクトログラムの描画 ---
ax2 = fig.add_subplot(gs[1, 0]) # スペクトログラム本体
ax2_cb = fig.add_subplot(gs[1, 1]) # カラーバー専用
n_fft = 2048
hop_length = 512
n_mels = 128
mel_spec = librosa.feature.melspectrogram(
y=audio_data,
sr=sr,
n_fft=n_fft,
hop_length=hop_length,
n_mels=n_mels,
power=2.0,
)
mel_db = librosa.power_to_db(mel_spec, ref=np.max)
img = librosa.display.specshow(
mel_db,
sr=sr,
hop_length=hop_length,
x_axis="time",
y_axis="mel",
ax=ax2,
)
cb = plt.colorbar(img, cax=ax2_cb, format="%+2.0f dB")
cb.set_label("dB")
ax2.set_title("Mel Spectrogram")
ax2.set_xlabel("Time (s)")
ax2.set_ylabel("Mel bin")
# --- 3段目:類似度推移の描画 ---
ax3 = fig.add_subplot(gs[2, 0])
colors = ["tab:blue", "tab:orange", "tab:green", "tab:red", "tab:purple"]
for i, text in enumerate(text_queries):
ax3.plot(
timestamps,
similarities[:, i],
label=f'"{text}"',
linewidth=2,
color=colors[i % len(colors)],
)
ax3.set_title("Text-Audio Similarity over Time (CLAP)")
ax3.set_xlabel("Time (seconds)")
ax3.set_ylabel("Cosine Similarity")
ax3.set_xlim(0, total_duration)
ax3.legend(loc="upper right", frameon=True, shadow=True)
ax3.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# =========================================================
# 全体実行
# =========================================================
def main() -> None:
# 検索したいテキスト
text_queries: List[str] = [
"Water flowing",
"Birdsong",
"dog barking", # 今回の音とは関係のないテキストも入れる
]
# スライディングウィンドウ設定
window_size_sec: float = 3.0 # 解析する窓の長さ(秒)
step_size_sec: float = 1.0 # 窓をずらす幅(秒)
# デバイス・モデルロード
device = setup_device()
model, processor = load_clap_model(device)
# 音声アップロード&処理
audio_data, sr, total_duration = process_audio_data()
# 音声が正しく読み込めている場合のみ、後段の類似度計算&可視化を実行
if audio_data is None or sr is None or total_duration is None:
print("Audio data not loaded. Skipping similarity analysis.")
return
# 類似度の計算
timestamps, similarities = compute_similarity_over_time(
device=device,
model=model,
processor=processor,
audio=audio_data,
sr=sr,
texts=text_queries,
win_sec=window_size_sec,
step_sec=step_size_sec,
)
# 可視化
plot_similarity_over_time(
audio_data=audio_data,
sr=sr,
total_duration=total_duration,
timestamps=timestamps,
similarities=similarities,
text_queries=text_queries,
)
if __name__ == "__main__":
main()
実験2コード
import os
import shutil
import zipfile
import urllib.request
from typing import Dict, List, Tuple, Optional
import librosa
import numpy as np
import pandas as pd
import torch
import umap
from matplotlib import pyplot as plt
from matplotlib.lines import Line2D
from matplotlib.patches import Patch
from matplotlib.colors import TwoSlopeNorm
from transformers import ClapModel, ClapProcessor
# 高解像度なPNGでグラフを出力するための設定
import matplotlib_inline.backend_inline
matplotlib_inline.backend_inline.set_matplotlib_formats("retina")
# ============================================================
# ESC-50の取得URLとメジャーカテゴリ対応
# ============================================================
ESC50_ZIP_URL = "https://github.com/karolpiczak/ESC-50/archive/master.zip"
MAJOR_CATEGORIES: Dict[str, List[str]] = {
"Animals": [
"dog", "rooster", "pig", "cow", "frog",
"cat", "hen", "insects", "sheep", "crow"
],
"Natural": [
"rain", "sea_waves", "crackling_fire", "crickets",
"chirping_birds", "water_drops", "wind", "pouring_water",
"toilet_flush", "thunderstorm"
],
"Human": [
"crying_baby", "sneezing", "clapping", "breathing",
"coughing", "footsteps", "laughing", "brushing_teeth",
"snoring", "drinking_sipping"
],
"Interior": [
"door_wood_knock", "mouse_click", "keyboard_typing", "door_wood_creaks",
"can_opening", "washing_machine", "vacuum_cleaner", "clock_alarm",
"clock_tick", "glass_breaking"
],
"Exterior": [
"helicopter", "chainsaw", "siren", "car_horn",
"engine", "train", "church_bells", "airplane",
"fireworks", "hand_saw"
],
}
# ============================================================
# ESC-50 データセット準備(削除 + ダウンロード + 解凍)
# ============================================================
def prepare_esc50_dataset(
zip_url: str = ESC50_ZIP_URL,
zip_path: str = "esc50_master.zip",
dataset_dir: str = "ESC-50-master",
extract_dir: str = ".",
force_download: bool = False,
) -> None:
"""ESC-50 データセットを準備する。
既にデータセットが存在する場合は、デフォルトではダウンロード・解凍をスキップする。
強制的に再取得したい場合は force_download=True を指定する。
Args:
zip_url (str): ESC-50のzipのURL
zip_path (str): ダウンロードしたzipファイルを保存するローカルパス
dataset_dir (str): 解凍後に作成されるデータセットディレクトリ名
extract_dir (str): zip を展開する先のディレクトリ
force_download (bool): True の場合、既存データがあっても削除して再ダウンロードする
"""
# 既存データがあり、再取得しない場合
if os.path.isdir(dataset_dir) and not force_download:
print(f"ESC-50 dataset already exists. Skipping download: {dataset_dir}")
return
# 強制再取得 or 初回取得
if os.path.isdir(dataset_dir):
print("Removing existing ESC-50 dataset...")
shutil.rmtree(dataset_dir)
if os.path.exists(zip_path):
os.remove(zip_path)
# ダウンロード
print("Downloading ESC-50 dataset...")
urllib.request.urlretrieve(zip_url, zip_path)
# 解凍
print("Unzipping ESC-50 dataset...")
with zipfile.ZipFile(zip_path, "r") as zf:
zf.extractall(extract_dir)
print("ESC-50 dataset prepared:", dataset_dir)
# ============================================================
# デバイス設定
# ============================================================
def setup_device() -> torch.device:
"""PyTorch の実行デバイス(CPU または CUDA)を取得する
Returns:
torch.device: 使用するデバイス
"""
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
return device
# ============================================================
# CLAP モデルのロード
# ============================================================
def load_clap_model(
device: torch.device,
model_id: str = "laion/clap-htsat-unfused",
) -> Tuple[ClapModel, ClapProcessor]:
"""CLAP モデルとプロセッサをロードする。
Args:
device (torch.device): モデルを配置するデバイス
model_id (str): Hugging Face上のCLAPモデルID
Returns:
Tuple[ClapModel, ClapProcessor]: ロード済み CLAP モデルとプロセッサ
"""
print("Loading CLAP model...")
model = ClapModel.from_pretrained(model_id).to(device)
processor = ClapProcessor.from_pretrained(model_id)
print("Model loaded.")
return model, processor
# ============================================================
# テキストプロンプト生成
# ============================================================
def make_prompt(category_name: str) -> str:
"""ESC-50のサブクラス名から簡単な英語プロンプトを生成する。
サブクラス名は基本的に単語をアンダースコアで繋いでいるので、
空白に置き換えつつ、文章の形に整形する
Args:
category_name (str): ESC-50のサブクラス名(例: "dog", "sea_waves")
Returns:
str: 音の説明文となる短い英文
"""
text = category_name.replace("_", " ")
animal_set = {
"dog", "rooster", "pig", "cow", "frog",
"cat", "hen", "insects", "sheep", "crow"
}
natural_set = {
"rain", "sea_waves", "crackling_fire", "crickets",
"chirping_birds", "water_drops", "wind",
"pouring_water", "toilet_flush", "thunderstorm"
}
human_set = {
"crying_baby", "sneezing", "clapping", "breathing",
"coughing", "footsteps", "laughing",
"brushing_teeth", "snoring", "drinking"
}
if category_name in animal_set:
return f"The sound of a {text}."
if category_name in natural_set:
return f"A recording of {text}."
if category_name in human_set:
return f"A human {text} sound."
return f"The sound of {text}."
# ============================================================
# ESC-50 音声 & テキストのロード
# ============================================================
def load_esc50_audio_and_text(
samples_per_subclass: int = 50, # -- サンプル数を変更する場所
target_sr: int = 48000,
max_duration: float = 5.0,
) -> Tuple[
List[np.ndarray],
List[str],
List[str],
List[str],
List[str],
List[str],
]:
"""ESC-50 から音声データとテキストプロンプトを読み込む。
Args:
samples_per_subclass (int): 各サブクラスから読み込む音声の最大数
target_sr (int): 音声を読み込む際のサンプリングレート
max_duration (float): 各音声クリップの最大長(秒)
Returns:
Tuple[List[np.ndarray], List[str], List[str], List[str], List[str], List[str]]:
以下の6要素のタプル:
- audio_clips: 音声波形(numpy配列)のリスト
- fine_labels_audio: 各音声の細分類カテゴリ名
- major_labels_audio: 各音声のメジャーカテゴリ名
- subclass_list: サブクラス名(テキスト埋め込み用に1つずつ)
- major_labels_text: サブクラスごとのメジャーカテゴリ
- text_prompts: サブクラスごとのプロンプト
"""
df = pd.read_csv("ESC-50-master/meta/esc50.csv")
audio_clips = []
fine_labels_audio = []
major_labels_audio = []
subclass_list = []
major_labels_text = []
text_prompts = []
print(f"Loading up to {samples_per_subclass} audio samples per subclass...\n")
max_len = int(target_sr * max_duration)
for major_name, subclasses in MAJOR_CATEGORIES.items():
print(f"[Major] {major_name}")
for subclass in subclasses:
rows = df[df["category"] == subclass].head(samples_per_subclass)
if rows.empty:
print(f" - WARNING: No rows for {subclass}")
continue
# テキスト側(各サブクラス 1つ)
subclass_list.append(subclass)
major_labels_text.append(major_name)
text_prompts.append(make_prompt(subclass))
count = 0
for _, row in rows.iterrows():
filepath = os.path.join("ESC-50-master/audio", row["filename"])
try:
y, _ = librosa.load(filepath, sr=target_sr, duration=max_duration)
y = np.pad(y, (0, max_len - len(y))) if len(y) < max_len else y[:max_len]
audio_clips.append(y)
fine_labels_audio.append(subclass)
major_labels_audio.append(major_name)
count += 1
except Exception as e: # noqa: BLE001
print(f" - ERROR loading {filepath}: {e}")
print(f" - {subclass:18s}: loaded {count}")
print(f"\nTotal loaded audio samples: {len(audio_clips)}")
print(f"Total subclasses: {len(subclass_list)}")
return (
audio_clips,
fine_labels_audio,
major_labels_audio,
subclass_list,
major_labels_text,
text_prompts,
)
# ============================================================
# CLAP 埋め込み(Audio)
# ============================================================
def encode_audio_in_batches(
model: ClapModel,
processor: ClapProcessor,
device: torch.device,
audio_clips: List[np.ndarray],
batch_size: int = 64,
sr: int = 48000,
) -> np.ndarray:
"""音声リストをバッチ処理で CLAP 埋め込みに変換する。
Args:
model (ClapModel): CLAPモデル
processor (ClapProcessor): CLAPプロセッサ
device (torch.device): 実行デバイス
audio_clips (List[np.ndarray]): 音声波形のリスト
batch_size (int): バッチサイズ
sr (int): サンプリングレート
Returns:
np.ndarray: 音声埋め込み配列(shape: [N, D])
"""
model.eval()
outputs = []
with torch.no_grad():
for i in range(0, len(audio_clips), batch_size):
batch = audio_clips[i:i + batch_size]
inputs = processor(audios=batch, sampling_rate=sr, return_tensors="pt", padding=True)
inputs = {k: v.to(device) for k, v in inputs.items()}
embeds = model.get_audio_features(**inputs)
embeds = embeds / embeds.norm(p=2, dim=-1, keepdim=True)
outputs.append(embeds.cpu())
return torch.cat(outputs, dim=0).numpy()
# ============================================================
# CLAP 埋め込み(Text)
# ============================================================
def encode_text_in_batches(
model: ClapModel,
processor: ClapProcessor,
device: torch.device,
text_list: List[str],
batch_size: int = 64,
) -> np.ndarray:
"""テキストリストをバッチ処理で CLAP 埋め込みに変換する。
Args:
model (ClapModel): CLAPモデル
processor (ClapProcessor): CLAPプロセッサ
device (torch.device): 実行デバイス
audio_clips (List[np.ndarray]): 音声波形のリスト
batch_size (int): バッチサイズ
sr (int): サンプリングレート
Returns:
np.ndarray: テキスト埋め込み配列(shape: [M, D])。
"""
model.eval()
outputs = []
with torch.no_grad():
for i in range(0, len(text_list), batch_size):
batch = text_list[i:i + batch_size]
inputs = processor(text=batch, return_tensors="pt", padding=True)
inputs = {k: v.to(device) for k, v in inputs.items()}
embeds = model.get_text_features(**inputs)
embeds = embeds / embeds.norm(p=2, dim=-1, keepdim=True)
outputs.append(embeds.cpu())
return torch.cat(outputs, dim=0).numpy()
# ============================================================
# UMAP による次元圧縮
# ============================================================
def run_umap(
audio_embeds: np.ndarray,
text_embeds: np.ndarray,
n_neighbors: int = 80,
min_dist: float = 1,
) -> Tuple[np.ndarray, np.ndarray]:
"""音声埋め込みとテキスト埋め込みを連結し、UMAPで2次元に変換する。
Args:
audio_embeds (np.ndarray): 音声埋め込み(N, D)
text_embeds (np.ndarray): テキスト埋め込み(M, D)
n_neighbors (int): 近傍点数
min_dist (float): 低次元空間での点間距離の最小値
Returns:
Tuple[np.ndarray, np.ndarray]:
UMAP により得た2次元座標 (audio_xy, text_xy)
"""
print("\nRunning UMAP...")
combined = np.concatenate([audio_embeds, text_embeds], axis=0)
reducer = umap.UMAP(
n_components=2,
n_neighbors=n_neighbors,
min_dist=min_dist,
metric="cosine",
random_state=42,
)
reduced = reducer.fit_transform(combined)
audio_xy = reduced[: len(audio_embeds)]
text_xy = reduced[len(audio_embeds):]
return audio_xy, text_xy
# ============================================================
# UMAP次元圧縮結果のプロット
# ============================================================
def plot_joint_embeddings(
audio_xy: np.ndarray,
text_xy: np.ndarray,
fine_labels_audio: List[str],
major_labels_audio: List[str],
subclass_list: List[str],
major_labels_text: List[str],
) -> None:
"""音声埋め込みとテキスト埋め込みの 2 次元空間を可視化する。
Args:
audio_xy (np.ndarray): 音声埋め込みの2次元座標
text_xy (np.ndarray): テキスト埋め込みの2次元座標
fine_labels_audio (List[str]): 音声のサブクラス名
major_labels_audio (List[str]): 音声のメジャーカテゴリ名
subclass_list (List[str]): テキスト埋め込みに対応するサブクラス名
major_labels_text (List[str]): テキスト埋め込みのメジャーカテゴリ名
"""
print("Plotting...")
plt.figure(figsize=(13, 10))
ax = plt.gca()
unique_majors = list(MAJOR_CATEGORIES.keys())
cmap = plt.get_cmap("Dark2")
colors = {major: cmap(i) for i, major in enumerate(unique_majors)}
# Audio → Text のリンク線
subclass_to_text_idx = {s: i for i, s in enumerate(subclass_list)}
for i, subclass in enumerate(fine_labels_audio):
if subclass in subclass_to_text_idx:
j = subclass_to_text_idx[subclass]
ax.plot(
[audio_xy[i, 0], text_xy[j, 0]],
[audio_xy[i, 1], text_xy[j, 1]],
color="gray",
alpha=0.1,
linewidth=0.5,
zorder=1,
)
# Audio / Text 散布図
for major in unique_majors:
idx_a = [i for i, m in enumerate(major_labels_audio) if m == major]
idx_t = [i for i, m in enumerate(major_labels_text) if m == major]
c = colors[major]
if idx_a:
ax.scatter(audio_xy[idx_a, 0], audio_xy[idx_a, 1],
color=c, marker="o", s=25, alpha=0.8,
edgecolors="white", linewidth=0.4, zorder=2,)
if idx_t:
ax.scatter(text_xy[idx_t, 0], text_xy[idx_t, 1],
color=c, marker="^", s=80, alpha=1.0,
edgecolors="black", linewidth=0.8, zorder=3)
# テキストラベル
for i, subclass in enumerate(subclass_list):
x, y = text_xy[i]
ax.text(
x, y + 0.7, subclass,
fontsize=10, ha="center", va="bottom",
color="black",
bbox=dict(
boxstyle="round,pad=0.2", fc="white", edgecolor="none", alpha=0.8
),
zorder=4
)
# マーカー凡例
marker_legend = [
Line2D([0], [0], marker="o", color="w",
label="Audio sample", markerfacecolor="gray", markersize=8),
Line2D([0], [0], marker="^", color="w",
label="Text prompt (1 per subclass)", markerfacecolor="gray",
markeredgecolor="black", markersize=9),
Line2D([0], [0], color="gray", lw=1, label="Pair link"),
]
marker_legend_obj = ax.legend(
handles=marker_legend,
loc="lower right",
frameon=True,
title="Modality",
fontsize=9,
)
ax.add_artist(marker_legend_obj)
# 色 = メジャーカテゴリの凡例
category_patches = [
Patch(facecolor=colors[major], edgecolor="black", label=major)
for major in unique_majors
]
ax.legend(
handles=category_patches,
loc="upper right",
frameon=True,
title="Major category",
fontsize=9,
)
plt.title("CLAP Joint Embedding Space (ESC-50)")
plt.grid(True, linestyle="--", alpha=0.2)
plt.xticks([])
plt.yticks([])
plt.tight_layout()
plt.show()
# ============================================================
# 類似度行列の可視化(ヒートマップ)
# ============================================================
def build_major_color_map() -> Dict[str, tuple]:
"""UMAP と同じ Dark2 でメジャーカテゴリ→色を作る。"""
unique_majors = list(MAJOR_CATEGORIES.keys())
cmap = plt.get_cmap("Dark2")
return {major: cmap(i) for i, major in enumerate(unique_majors)}
def plot_audio_text_similarity_heatmap(
audio_embeds: np.ndarray,
text_embeds: np.ndarray,
fine_labels_audio: List[str],
major_labels_audio: List[str],
subclass_list: List[str],
major_labels_text: List[str],
major_to_color: Dict[str, tuple],
y_tick_step: int = 40,
cmap: str = "RdBu_r",
title: str = "Cosine similarity heatmap (Audio x Text prompts)",
) -> None:
"""音声×テキストの全ペア cosine 類似度を、データに忠実にヒートマップ表示する。
"""
# --- 類似度行列 ---
sim = audio_embeds @ text_embeds.T # [N, M]
# サブクラスの基準順(メジャー→サブクラス)
desired_order = [s for majors in MAJOR_CATEGORIES.values() for s in majors]
subclass_rank = {s: r for r, s in enumerate(desired_order)}
# --- x軸(テキスト) ---
text_idx_map = {s: i for i, s in enumerate(subclass_list)}
x_order = [text_idx_map[s] for s in desired_order if s in text_idx_map]
x_labels = [subclass_list[i] for i in x_order]
x_majors = [major_labels_text[i] for i in x_order]
sim_x = sim[:, x_order]
# --- y軸(音声):major → subclass → 元順 ---
y_order = sorted(
range(len(fine_labels_audio)),
key=lambda i: (subclass_rank.get(fine_labels_audio[i], 10**9), i),
)
sim_xy = sim_x[y_order, :]
y_labels = [fine_labels_audio[i] for i in y_order]
y_majors = [major_labels_audio[i] for i in y_order]
# --- 正規化 ---
vmin = float(sim_xy.min())
vmax = float(sim_xy.max())
if vmin < 0.0 < vmax:
norm = TwoSlopeNorm(vmin=vmin, vcenter=0.0, vmax=vmax)
else:
norm = None
# --- 描画 ---
plt.figure(figsize=(14, 10))
ax = plt.gca()
im = ax.imshow(
sim_xy,
cmap=cmap,
norm=norm,
vmin=None if norm else vmin,
vmax=None if norm else vmax,
interpolation="nearest",
aspect="auto",
)
plt.colorbar(im, ax=ax, fraction=0.025, pad=0.02, label="cosine similarity")
ax.set_title(title)
ax.set_xlabel("Text prompt (subclass)")
ax.set_ylabel("Audio samples (subclass label)")
# --- x軸ラベル ---
ax.set_xticks(np.arange(len(x_labels)))
ax.set_xticklabels(x_labels, rotation=70, ha="right", fontsize=9)
for tick, major in zip(ax.get_xticklabels(), x_majors):
tick.set_color(major_to_color[major])
tick.set_fontweight("bold")
# --- y軸ラベル(間引き) ---
y_tick_step = max(1, y_tick_step)
y_ticks = np.arange(0, len(y_labels), y_tick_step)
ax.set_yticks(y_ticks)
ax.set_yticklabels([y_labels[i] for i in y_ticks], fontsize=9)
for tick, i in zip(ax.get_yticklabels(), y_ticks):
tick.set_color(major_to_color[y_majors[i]])
tick.set_fontweight("bold")
# --- x方向:major 境界(縦線) ---
count = 0
for major, subs in MAJOR_CATEGORIES.items():
count += sum(1 for s in subs if s in text_idx_map)
ax.axvline(count - 0.5, color="white", linewidth=1.2, alpha=0.9)
# --- y方向:subclass / major 境界(横線) ---
for i in range(1, len(y_labels)):
if y_labels[i] != y_labels[i - 1]:
# subclass 境界
ax.axhline(i - 0.5, color="white", linewidth=0.5, alpha=0.35)
# major 境界(太線)
if y_majors[i] != y_majors[i - 1]:
ax.axhline(i - 0.5, color="white", linewidth=1.5, alpha=0.9)
plt.tight_layout()
plt.show()
print(f"[heatmap range] vmin={vmin:.4f}, vmax={vmax:.4f}")
# ============================================================
# メイン処理
# ============================================================
def main() -> None:
"""ESC-50データの準備から、CLAPによる埋め込み計算、UMAP可視化、類似度行列可視化までを実行する。"""
# データ準備
prepare_esc50_dataset()
# デバイス・モデルロード
device = setup_device()
model, processor = load_clap_model(device)
# ESC-50 データ読み込み
(
audio_clips,
fine_labels_audio,
major_labels_audio,
subclass_list,
major_labels_text,
text_prompts,
) = load_esc50_audio_and_text()
# 埋め込み
audio_embeds = encode_audio_in_batches(model, processor, device, audio_clips)
text_embeds = encode_text_in_batches(model, processor, device, text_prompts)
# UMAP
audio_xy, text_xy = run_umap(audio_embeds, text_embeds)
# UMAPプロット
plot_joint_embeddings(
audio_xy, text_xy,
fine_labels_audio, major_labels_audio,
subclass_list, major_labels_text,
)
# 類似度行列プロット
major_to_color = build_major_color_map()
plot_audio_text_similarity_heatmap(
audio_embeds=audio_embeds,
text_embeds=text_embeds,
fine_labels_audio=fine_labels_audio,
major_labels_audio=major_labels_audio,
subclass_list=subclass_list,
major_labels_text=major_labels_text,
major_to_color=major_to_color,
y_tick_step=40,
cmap="RdBu_r",
)
if __name__ == "__main__":
main()
Footnotes
-
補足:本記事で使用しているlaion/clap-htsat-unfusedは、LAION-Audio-630Kという大規模データセットで事前学習されたモデルです。このデータセットには Freesound 由来の音源が含まれており、ESC-50 も同じく Freesound から構成されています。そのため、厳密には ESC-50 の一部音源が事前学習データに含まれている可能性があります。ただし、本記事の目的はモデルの挙動や表現空間の理解であり、リークを完全に排除した性能評価を行うものではありません。 ↩